
Trainer vs SFTTrainer: The Complete LLM Training Stack for Financial Services
How Hedge Funds and Quant Teams Navigate 15+ Training Libraries to Build Custom AI Models

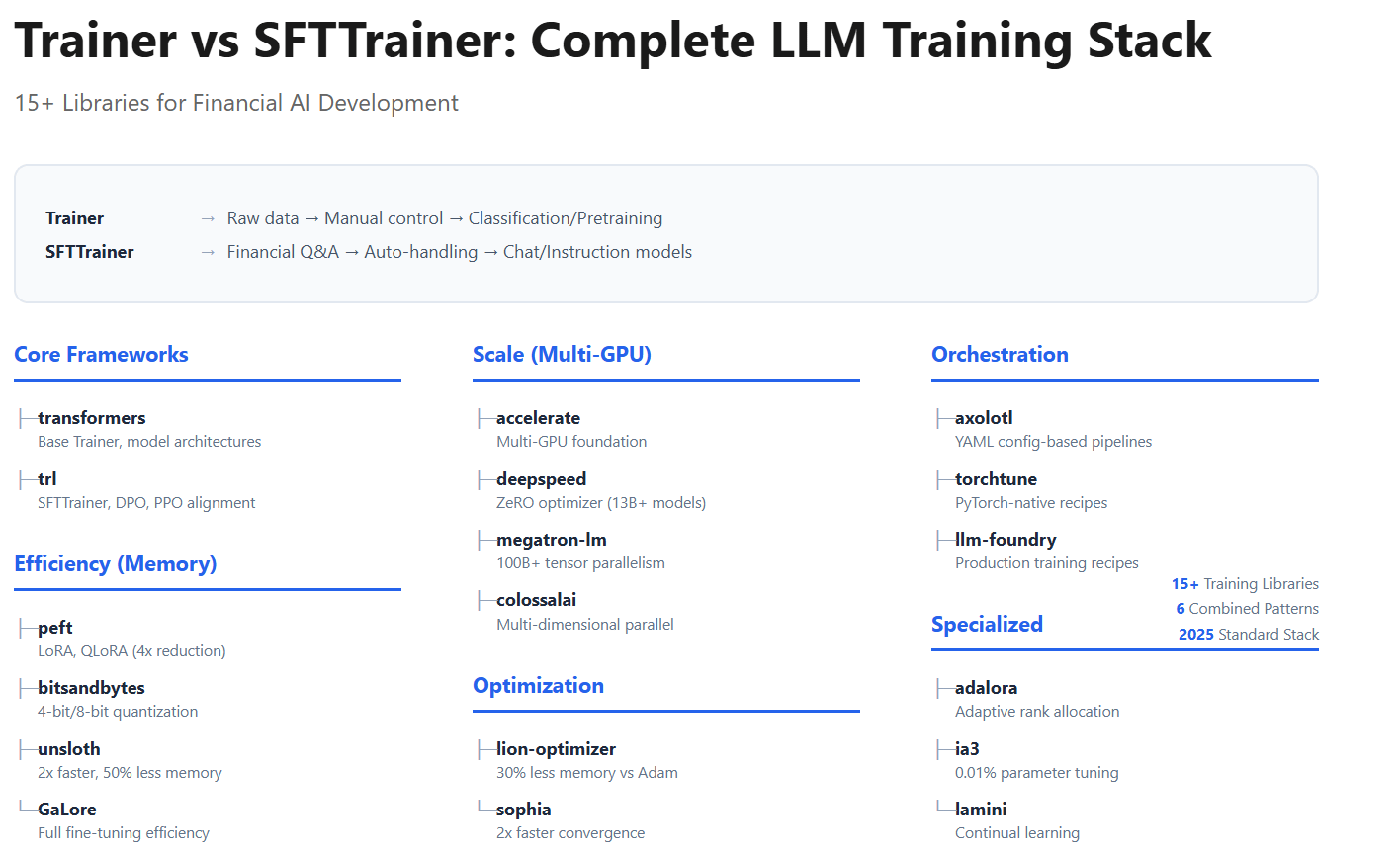
SECTION 0: The 30-Second Version
Financial Data → Training Framework → Custom Financial AI Model
Two Core Paths:
├─ Trainer: Raw market data → Manual control → Classification/pretraining
└─ SFTTrainer: Financial Q&A → Auto-handling → Chat/instruction models
Supporting Libraries (15+):
├─ Efficiency: PEFT, bitsandbytes, unsloth
├─ Scale: DeepSpeed, megatron-lm, colossalai
├─ Optimization: GaLore, lion-optimizer, sophia
└─ Orchestration: axolotl, torchtune, llm-foundry
What: Trainer handles general supervised learning; SFTTrainer specializes in instruction-tuning. Both integrate with 15+ specialized libraries.
Why: Modern financial AI requires combining multiple libraries. SFTTrainer plus LoRA plus 4-bit quantization is now standard for hedge fund chatbots.
How: Choose core trainer, add efficiency layer (LoRA), add scale layer (DeepSpeed if needed), wrap in orchestration tool (axolotl for production).
That’s it. Now let’s break it down.
Understanding the Core Training Libraries
Trainer from transformers:
Purpose: General supervised training for continued pretraining
Best for: MLM, classification, token classification on market data
Data needs: Pre-tokenized inputs with manual formatting
When hedge funds use it: Training sentiment models on Fed transcripts, entity extraction from 10-Ks
SFTTrainer from TRL:
Purpose: Supervised fine-tuning for chat and instruction models
Best for: Portfolio advisors, compliance chatbots, earnings summarizers
Data needs: Raw text with automatic chat template handling
When quant teams use it: Building conversational financial analysts, Q&A systems
What just happened in the industry:
2018: Only Trainer existed (hedge funds manually coded everything)
2023: SFTTrainer launched (80% automation for financial chatbots)
2025: Combined stacks became standard (SFTTrainer plus LoRA plus quantization)
Common mistakes:
Using Trainer for chat models (loses automatic template handling)
Using SFTTrainer for raw time series (wrong tool for numeric data)
Not combining with efficiency libraries (burns GPU budget unnecessarily)
The Complete Library Ecosystem
Core Training Frameworks
transformers (Hugging Face):
Status: Foundation for everything
Contains: Model architectures, base Trainer class
Financial use: All custom model development starts here
trl (Transformer Reinforcement Learning):
Status: Standard for post-training and alignment
Contains: SFTTrainer, DPOTrainer, PPOTrainer for RLHF
Financial use: Chat-based portfolio advisors, compliance assistants
Try it yourself: Pick transformers.Trainer when fine-tuning classification models on financial documents. Pick trl.SFTTrainer when building conversational financial analysts.
Efficiency Libraries (Memory Reduction)
peft (Parameter-Efficient Fine-Tuning):
Core capability: LoRA, QLoRA, Prefix Tuning, IA3
Status: Industry standard (used by 90% of hedge funds)
Memory savings: 4x reduction, trains only 0.1% of parameters
Financial impact: Enables 7B model training on single A100 instead of 8-GPU cluster
bitsandbytes:
Core capability: 4-bit and 8-bit quantization
Status: Standard for QLoRA training
Memory savings: 8x reduction for 4-bit models
Financial impact: Quant teams train 13B models on consumer GPUs (16GB)
unsloth:
Core capability: Optimized kernels for 2x faster LoRA
Status: Rising adoption (2024 breakthrough)
Speed improvement: 50% less memory, 2x training speed
Financial impact: Deploy sentiment models same day instead of next week
What just happened: Before peft (2020), hedge funds needed $100k GPU clusters for fine-tuning. After peft plus bitsandbytes (2023), same training runs on $2k consumer cards.
Distributed Training (Scale Up)
accelerate:
Core capability: Multi-GPU orchestration, mixed precision
Status: Foundation for all distributed training
Financial use: Automatic device placement when scaling beyond single GPU
deepspeed:
Core capability: ZeRO optimizer (stages 1-3), pipeline parallelism
Status: Best for large-scale training over 7B parameters
Memory savings: ZeRO-3 enables 100B models on 8 GPUs
Financial use: Hedge funds pretraining custom foundation models on proprietary trading data
megatron-lm (NVIDIA):
Core capability: Tensor and pipeline parallelism for 100B+ models
Status: Specialized for extreme scale
Financial use: Large institutions building GPT-4 scale proprietary models
colossalai:
Core capability: Multi-dimensional parallelism (combines all strategies)
Status: Alternative to DeepSpeed with easier API
Financial use: Research teams experimenting with efficient large-scale training
fairscale (Meta):
Core capability: FSDP (Fully Sharded Data Parallel)
Status: PyTorch-native alternative to DeepSpeed
Financial use: Teams preferring PyTorch ecosystem over Microsoft stack
When to scale:
Single GPU: Models under 7B with LoRA (most hedge fund use cases)
Multi-GPU with accelerate: 7B-13B full fine-tuning
DeepSpeed ZeRO-2: 13B-30B models
DeepSpeed ZeRO-3 or megatron: 70B+ models
Optimizer and Memory Libraries
GaLore (Gradient Low-Rank Projection):
Core capability: Memory-efficient full fine-tuning without LoRA
Status: Breakthrough 2024 research
Memory savings: Train full model with LoRA-level memory
Financial impact: Full fine-tuning on compliance datasets without parameter restrictions
lion-optimizer:
Core capability: Memory-efficient optimizer replacement for AdamW
Memory savings: 30% less memory than Adam
Financial use: When training large models hitting memory limits
sophia:
Core capability: Second-order optimizer
Speed improvement: 2x faster convergence (half the training steps)
Financial use: Rapid prototyping when compute time is bottleneck
apex (NVIDIA):
Core capability: Mixed precision FP16 training utilities
Status: Mature NVIDIA-specific optimizations
Financial use: Maximizing A100/H100 GPU efficiency
What just happened: Traditional Adam optimizer stores 2 copies of gradients. GaLore projects to low-rank space. Lion uses sign-based updates. Result: Same model quality, 50% less memory.
Orchestration and Config Management
axolotl:
Core capability: YAML-based unified training configs
Status: Community favorite for simplified pipelines
Financial use: Production training workflows, reproducible experiments
Why hedge funds use it: Declarative configs prevent code errors in production
torchtune (Meta):
Core capability: PyTorch-native fine-tuning with recipe system
Status: Official Meta library (2024)
Financial use: Llama-specific optimizations for financial domain adaptation
llm-foundry (MosaicML):
Core capability: End-to-end training recipes with Composer
Status: Production-grade pipeline framework
Financial use: Large institutions with dedicated ML infrastructure
Try it yourself: Start with axolotl if you prefer configuration files over Python code. It prevents common mistakes by validating configs before training starts.
Specialized Fine-Tuning Methods
adalora:
Core capability: Adaptive LoRA with dynamic rank allocation
Performance: Better than fixed-rank LoRA on complex tasks
Financial use: When standard LoRA underperforms on earnings analysis
ia3 (Infused Adapter):
Core capability: Even fewer parameters than LoRA
Parameter count: 0.01% vs LoRA’s 0.1%
Financial use: Ultra low-resource training for small hedge funds
lamini:
Core capability: Memory tuning and continual learning
Unique feature: Fact injection without catastrophic forgetting
Financial use: Updating models with new regulatory knowledge quarterly
Common mistakes:
Using standard LoRA when task needs adaptive rank (adalora)
Not exploring IA3 for memory-constrained environments
Forgetting continual learning when models need quarterly updates
Debugging and Profiling
pytorch-lightning:
Core capability: Training boilerplate reduction
Status: Mature abstraction layer
Financial use: Cleaner code for research teams
composer (MosaicML):
Core capability: 20+ training speedup algorithms
Performance: Faster convergence through algorithmic tricks
Financial use: Reducing training time from days to hours
Six Combined Usage Patterns for Financial Services
Pattern 1: LoRA + SFTTrainer (Industry Standard)
Stack: transformers + peft (LoRA) + trl (SFTTrainer)
When hedge funds use this:
Building portfolio analysis chatbots
Training on 10k-100k financial Q&A pairs
Single A100 GPU available
Need deployment within 1 week
Memory requirements: 24GB VRAM for 7B models
What happens: Base model loaded, LoRA adapters added to query/value projection layers, SFTTrainer handles chat formatting automatically, only 0.1% of parameters updated.
Benefits:
4x memory reduction versus full fine-tuning
Automatic chat template handling
Fast iteration cycles (hours not days)
Pattern 2: QLoRA + SFTTrainer (Budget Training)
Stack: transformers + bitsandbytes (4-bit) + peft (LoRA) + trl (SFTTrainer)
When quant teams use this:
Training 13B models on consumer GPUs
GPU budget under $5k
Rapid prototyping phase
No cloud compute access
Memory requirements: 16GB VRAM for 13B models, 10GB for 7B models
What happens: Model quantized to 4-bit NF4 format, gradients computed in bfloat16, LoRA adapters trained in higher precision, memory reduced 8x versus FP16.
Benefits:
Enables large model training on gaming GPUs
Cost savings: $2k local GPU vs $50k cloud spend
Same quality as full precision training
Common mistakes:
Not using prepare_model_for_kbit_training (crashes training)
Wrong compute dtype (use bfloat16 not float16)
Forgetting gradient checkpointing for 13B+ models
Pattern 3: DeepSpeed + Trainer (Multi-GPU Scale)
Stack: transformers + accelerate + deepspeed (ZeRO-3)
When financial institutions use this:
Training models over 30B parameters
Multi-GPU clusters available
Pretraining on proprietary trading data
Need maximum throughput
Memory requirements: Distributes across all GPUs, enables 70B models on 8x A100
What happens: ZeRO-3 shards optimizer states, gradients, and parameters across GPUs. Each GPU stores 1/N of model. Communication overhead managed automatically.
Configuration levels:
ZeRO-1: Shard optimizer only (minimal communication)
ZeRO-2: Shard optimizer plus gradients (moderate communication)
ZeRO-3: Shard everything including parameters (maximum memory savings)
Benefits:
Train 100B models without model parallelism complexity
CPU offloading for even larger models
Production-grade by Microsoft
Pattern 4: Unsloth + SFTTrainer (Maximum Speed)
Stack: unsloth + peft (LoRA) + trl (SFTTrainer)
When hedge funds use this:
Deployment deadline under 48 hours
Need fastest possible training
Willing to use newer library
LoRA sufficient for task
Memory requirements: 50% less than standard LoRA
What happens: Unsloth’s optimized kernels replace standard PyTorch operations. Fused attention, optimized backprop, custom CUDA kernels. 2x faster training speed.
Benefits:
Same-day model deployment possible
Half the GPU memory of standard LoRA
Compatible with existing SFTTrainer workflows
Performance gains for financial workloads: Sentiment model training: 8 hours → 4 hours. Compliance chatbot fine-tuning: 2 days → 1 day. Earnings summarization: 12 hours → 6 hours.
Pattern 5: Axolotl Config-Based (Production Pipelines)
Stack: axolotl (wraps transformers + peft + trl + deepspeed)
When financial teams use this:
Production model training pipelines
Need reproducibility across team
Prefer declarative over imperative code
Running regular retraining cycles
Configuration approach: YAML file specifies model, dataset, LoRA settings, training hyperparameters, evaluation metrics. Single command runs entire pipeline.
What happens: Axolotl validates config, loads model with specified quantization, applies LoRA, runs SFTTrainer with chat templates, evaluates on held-out set, saves adapters.
Benefits:
No Python coding required
Version control training configs
Prevents common integration mistakes
Easier for non-ML financial analysts
Common mistakes:
Not validating YAML syntax before long training runs
Missing required fields (crashes after hours)
Wrong path separators on Windows
Pattern 6: Full Post-Training Pipeline (SFT + DPO)
Stack: trl (SFTTrainer + DPOTrainer)
When institutions use this:
Building production-grade assistants
Have human preference data
Need alignment beyond supervised fine-tuning
Following state-of-the-art practices
Two-stage process: Stage 1 using SFTTrainer: Supervised fine-tuning on expert financial analyst demonstrations. Model learns task format and domain knowledge.
Stage 2 using DPOTrainer: Direct Preference Optimization on chosen versus rejected response pairs. Model aligns with human financial advisor preferences.
What happens: SFT creates base capability, DPO refines responses to match professional standards, reference model prevents distribution shift, KL divergence penalty maintains coherence.
Benefits:
Higher quality responses than SFT alone
Aligns with firm’s specific advisory style
Reduces hallucinations on financial facts
Follows latest alignment research
Data requirements:
SFT stage: 10k-100k financial Q&A demonstrations
DPO stage: 1k-10k preference pairs (chosen vs rejected)
Decision Framework for Financial Teams
Choose Trainer when:
Continued pretraining on Fed transcripts or SEC filings
Classification tasks (sentiment scoring, entity extraction)
Custom loss functions for financial forecasting
Token-level predictions for metric extraction
Choose SFTTrainer when:
Building conversational financial advisors
Instruction-tuning for portfolio analysis
Creating compliance Q&A systems
Fine-tuning report generation models
Add efficiency layer:
Always use PEFT (LoRA): 4x memory reduction, standard practice
Add bitsandbytes if GPU under 24GB: 8x memory reduction
Try unsloth if timeline under 1 week: 2x speed boost
Consider GaLore for full fine-tuning: no LoRA limitations
Add scale layer if needed:
Single GPU sufficient: 7B models with LoRA (most hedge funds)
Multiple GPUs needed: DeepSpeed for 13B+ models
Extreme scale: megatron-lm for 100B+ institutional models
Add orchestration:
axolotl: Production pipelines, team collaboration
torchtune: Llama-specific optimizations
llm-foundry: Enterprise-grade infrastructure
Evolution Timeline
2018: Trainer introduced (hedge funds manually coded all training)
2020: PEFT library released (LoRA made fine-tuning affordable for small firms)
2021: bitsandbytes launched (quantization enabled consumer GPU training)
2022: DeepSpeed ZeRO-3 released (large-scale training democratized)
2023: SFTTrainer launched in TRL (80% automation for instruction tuning)
2023: QLoRA published (4-bit plus LoRA became standard combination)
2024: Unsloth optimized kernels (2x speed improvement)
2024: GaLore research (full fine-tuning with LoRA-level memory)
2024: axolotl matured (config-based training became production standard)
Current standard (2025): SFTTrainer plus LoRA plus 4-bit quantization for chat models. Trainer plus DeepSpeed for pretraining. Axolotl for production orchestration.
Why this evolution matters: 2018: $100k GPU cluster required for fine-tuning. 2025: $2k consumer GPU sufficient. Result: Every hedge fund can build custom financial AI.
Additional Specialized Libraries
Continual Learning:
lamini enables updating models with new financial regulations quarterly without forgetting previous knowledge. Critical for compliance models.
Alternative Efficiency:
adalora provides adaptive rank allocation when standard fixed-rank LoRA underperforms on complex financial reasoning tasks.
ia3 offers ultra-parameter-efficient tuning (0.01% vs LoRA’s 0.1%) for extremely memory-constrained environments.
Optimizer Alternatives:
lion-optimizer reduces memory 30% versus AdamW when training large models hitting memory limits.
sophia provides 2x faster convergence through second-order optimization, halving training time.
Distributed Alternatives:
colossalai combines tensor, pipeline, and data parallelism with simpler API than DeepSpeed for research teams.
fairscale offers PyTorch-native FSDP for teams preferring PyTorch ecosystem over Microsoft’s DeepSpeed.
Framework Alternatives:
pytorch-lightning reduces boilerplate code for research teams prioritizing clean implementations.
composer provides 20+ algorithmic speedup methods for reducing training time through better convergence.
Key Takeaways
Core libraries:
Trainer: General supervised training with full control
SFTTrainer: Instruction tuning with 80% automation
Combine based on task: classification uses Trainer, chat uses SFTTrainer
Efficiency stack (always add):
PEFT (LoRA): 4x memory reduction, industry standard
bitsandbytes: 8x reduction for budget constraints
unsloth: 2x speed for tight deadlines
Scale stack (add when needed):
accelerate: Foundation for any multi-GPU work
DeepSpeed: 13B+ models, ZeRO-3 for 70B+
megatron-lm: 100B+ institutional foundation models
Orchestration (production use):
axolotl: Config-based pipelines, team collaboration
torchtune: Llama-specific optimizations
llm-foundry: Enterprise infrastructure
Emerging techniques:
GaLore: Full fine-tuning with LoRA memory
DPO: Alignment after SFT for production quality
lamini: Continual learning for quarterly updates
Standard 2025 stack for hedge funds: SFTTrainer plus LoRA plus 4-bit quantization equals custom financial chatbot in 48 hours on $2k GPU.
Next step: Choose your pattern based on constraints. Single GPU under 24GB: Pattern 2 (QLoRA + SFTTrainer). Multiple GPUs: Pattern 3 (DeepSpeed). Tight deadline: Pattern 4 (Unsloth). Production pipeline: Pattern 5 (Axolotl).
What’s your constraint? GPU budget, timeline, model size, or team coding preferences? Share which pattern fits your hedge fund’s situation.
References
Hugging Face Transformers Documentation (2025)
TRL (Transformer Reinforcement Learning) Library Specifications
PEFT: Parameter-Efficient Fine-Tuning Methods
QLoRA: Efficient Finetuning of Quantized LLMs (Dettmers et al., 2023)
Unsloth Performance Benchmarks (2024)
DeepSpeed ZeRO Optimization Documentation
GaLore: Memory-Efficient LLM Training via Gradient Low-Rank Projection (2024)
Axolotl Training Framework Documentation
Direct Preference Optimization (DPO) Research (Rafailov et al., 2023)
Financial LLM Training Best Practices (Industry Survey 2024)